Compare commits
10 Commits
75cf1e7f71
...
master
| Author | SHA1 | Date | |
|---|---|---|---|
| 16aad6005a | |||
| 02d994d781 | |||
| d231971595 | |||
| 54f5cafde1 | |||
| 1cb0677e49 | |||
| 321e006289 | |||
| a4fc00d228 | |||
| 07859359d3 | |||
| 9fd9e66340 | |||
| 8f73fcf829 |
17
.gitea/workflows/demo.yaml
Normal file
17
.gitea/workflows/demo.yaml
Normal file
@@ -0,0 +1,17 @@
|
||||
name: Blog Generation
|
||||
run-name: test site generation
|
||||
on: [push]
|
||||
|
||||
jobs:
|
||||
Explore-Gitea-Actions:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Check out repository code
|
||||
uses: actions/checkout@v4
|
||||
- run: echo "💡 The ${{ gitea.repository }} repository has been cloned to the runner."
|
||||
- run: echo "🖥️ The workflow is now ready to test your code on the runner."
|
||||
- name: List files in the repository
|
||||
run: |
|
||||
ls ${{ gitea.workspace }}
|
||||
- run: docker pull ghcr.io/gohugoio/hugo:v0.154.5
|
||||
- run: docker run -v ${PWD}:/project -u 1000:1000 ghcr.io/gohugoio/hugo:v0.154.5 build
|
||||
@@ -7,7 +7,7 @@ draft: false
|
||||
I wanted to get back into ARM assembler so I wrote my own strlen. And then I looked at the strlen() glibc uses and did not understand
|
||||
a single thing. So I sat down and figured it out.
|
||||
|
||||
XXX IMG HERE XXX
|
||||
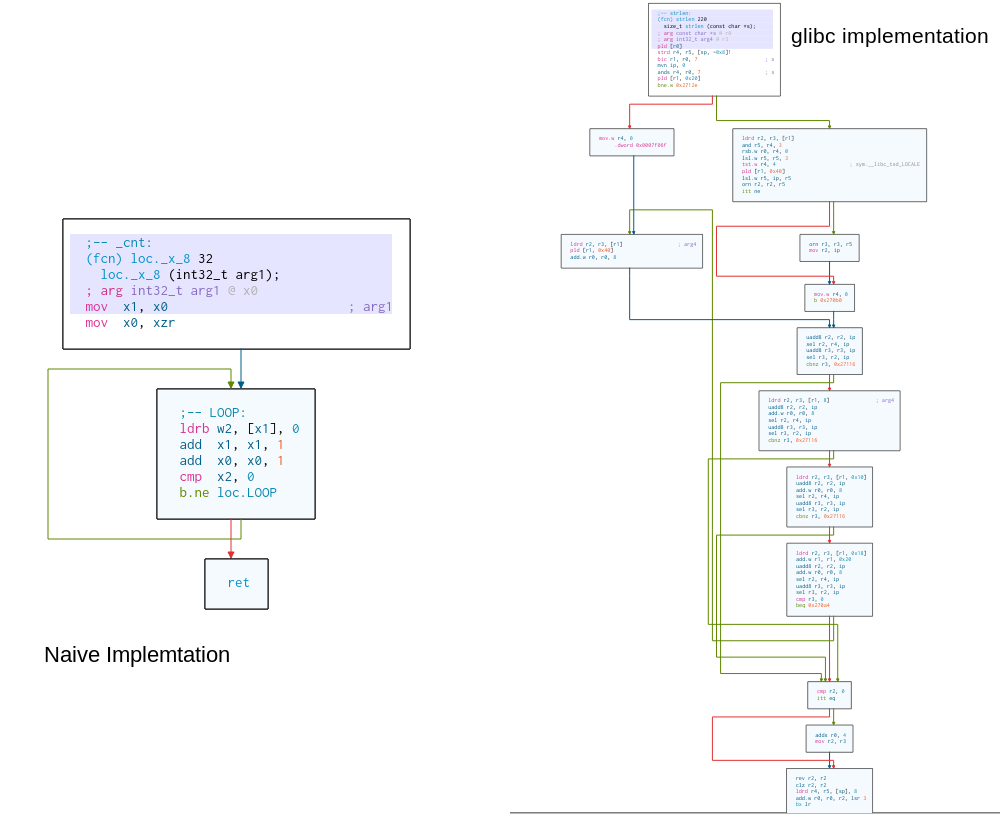
|
||||
|
||||
On the left you see a flow diagram of the building blocks of my naive implementation. On the right you see glibc's. You might
|
||||
notice that it is more complex. (How much faster it is, and which optimization exactly makes it fast is an interesting topic.
|
||||
@@ -22,7 +22,7 @@ The first thing I noticed about the inner loop is that it is unrolled. That is a
|
||||
because strlen does not clearly unroll as the input is cleanly divisible by word size. So on the end of every basic block there
|
||||
is a check which skips out of the loop and to the end where the result is calculated and returned.
|
||||
|
||||
XXX IMG HERE XXX
|
||||
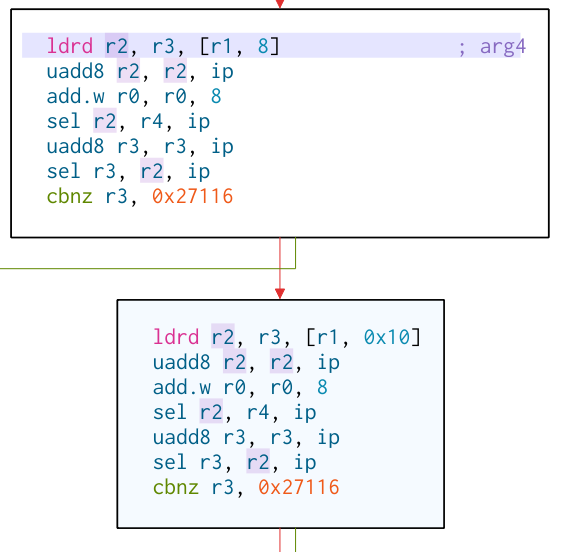
|
||||
|
||||
The basic blocks are basically identical. First the registers r2 and r3 are populated with the next two words to be checked for
|
||||
the null byte. Now r2 and r3 each contain one word (i.e. 4 bytes). How do you check whether there is a null byte *somewhere* in them?
|
||||
|
||||
103
content/posts/drive-by-contributions.md
Normal file
103
content/posts/drive-by-contributions.md
Normal file
@@ -0,0 +1,103 @@
|
||||
---
|
||||
title: "Drive By Contributions to Open Source Software"
|
||||
date: 2020-10-11T13:58:00+01:00
|
||||
draft: false
|
||||
---
|
||||
# Intro
|
||||
A few weeks ago an Microsoft employee made some statments that relying on email
|
||||
is [a barrier to entry](https://www.theregister.com/2020/08/25/linux_kernel_email/)
|
||||
to develop on the linux kernel. A lot of people didn't like that comment -- for
|
||||
whatever stupid reasons (microsoft? female? really liking email?)
|
||||
|
||||
There have been arguments in either side. I personally liked [this](https://www.labbott.name/blog/2020/09/01/emailgateway.html)
|
||||
and [this](https://lobste.rs/s/0jt525/relying_on_plain_text_email_is_barrier#c_bv3txg]) one best.
|
||||
|
||||
But I assume that most open source contributitor do not want to be long term,
|
||||
core members of that project. They are first and foremost users who happend
|
||||
to stumble upon a problem and just want to fix it. They want to a) fix that
|
||||
problem and right now (for themselves) and continue working on their actual
|
||||
work and b) save others from running into the same problem again.
|
||||
|
||||
They are drive-by contributers, who _need_ an easy, common way to submit their
|
||||
issues and patches.
|
||||
|
||||
# My contributions to other software
|
||||
|
||||
1. I was annoyed by thunderbird being slow to filter many mails[0] so I switched
|
||||
to another email client. It wasn't very stable but it was fast. It had a bug when
|
||||
replying to mails from an famous, not to be named, email client starting with "ou"
|
||||
and ending with "ook". I filed the bug but because I wasn't familiar with the
|
||||
language the mail client was written in I didn't send in a patch myself. but it
|
||||
got fixed anyhow and all was well.
|
||||
|
||||
2. To help people write code for embedded systems I was supposed make the emulator
|
||||
easier to grasp. That meant adding an GUI where you could see the blinkenlights.
|
||||
And because it was meant for university students it had to run on what people
|
||||
actually use -- windows. (If only this story had took place in 2021, the year
|
||||
of linux on the desktop). The emulator was almost cross platform -- there was only
|
||||
one linux specific path left. I filed an issue, sent in the patch. It was merged
|
||||
and all was well.
|
||||
|
||||
3. In another instance I had a bug where some customers could not be allow-listed
|
||||
in a popular CMS. Turns out that allowlist checked IPv6 addresses case
|
||||
sensitive. I filed a bug, sent in a patch. It got merged and all was well.
|
||||
|
||||
4. My earliest contribution to open source was in an TLS library which only connected
|
||||
to the first IP of an domain. I sent in a patch request, it wasn't up to the
|
||||
coding standart. I didn't care much, since I had my local fork. Some time later
|
||||
that code in the library was rewritten anyway and all was well.
|
||||
|
||||
5. An freelancer did large portions for $PRODUCT in my company. His code wrapping
|
||||
the Zend/Laminas Framework had an error where for plaintext only mails it still
|
||||
sent multipart/alternative which meant that no mail client could show the content.
|
||||
I sent in the patch, it got fixed and all was splendid.
|
||||
|
||||
In none of these cases did/do I intent to become a maintainer. I wouldn't rule it
|
||||
out to become a maintainer[1] but all these projects are just building blocks used for
|
||||
whatever my actual job at that time is.
|
||||
|
||||
# How DID I submit patches to these projects?
|
||||
|
||||
Now what where the barriers of entry to each and every single one of these projects?
|
||||
It would be ludicrious to try and see anything meaningful for all (FOSS) projects
|
||||
in the world from such a small sample size, so I am only going to give my very
|
||||
subjective view.
|
||||
|
||||
In all but two cases the whole communication happend on github (I will talk about
|
||||
github in a minute). One was the freelancer where I could do anything from writing
|
||||
an email, filing an issue on gitlab to just driving over to his house. The other
|
||||
one was a "proper" email based workflow.
|
||||
|
||||
Many people have already stated what they think the barriers to entry are for
|
||||
sending patches over mail, there is no need to rehash them. Let me just say that
|
||||
for some misguided non-sexual fascination with masochism I wanted to learn mutt
|
||||
at that time and still found it hard to send in the patches. I actually practiced
|
||||
sending them to another account of mine first. And all that only after *finding*
|
||||
in outdated wiki pages where the mailing list is in the first place.
|
||||
|
||||
For the rest I have used github (and similar). Github has by no means a perfect
|
||||
UX. But things like issue templates, a interface which I am accustomed from the
|
||||
last one thousand, three houndred and forty seven projects I checked out do help
|
||||
people to submit a ok-ish issue easily.
|
||||
|
||||
# Conclusion
|
||||
|
||||
I think the discussion about Sarah Novotny's plea/suggestion to move away from
|
||||
an email only way of submitting issues & patches missed the point that most
|
||||
projects have a long tail of single-issue contributers. I personally am one of
|
||||
these drive by contributors.
|
||||
|
||||
Personally I don't think that everyone should migrate over to Microsoft owned,
|
||||
working with ICE github. Such an huge concentraion of basically all software on
|
||||
one single platform is never good. HOWEVER even with all those flaws it would
|
||||
solve the issue at hand: removing barriers to entry for first time contributors
|
||||
to open source
|
||||
|
||||
|
||||
# Footnotes
|
||||
[0] think an outage causing a couple hundred mails to be sent out during the
|
||||
night. Then as I walk into the office, hearing about the outage and opening up
|
||||
Thunderbird having it freeze for multiple seconds as it sorts these mails into
|
||||
the "cron & other junk folder". Seconds which make me very nervous as I can't
|
||||
start to figure out the actual incident.
|
||||
[1] well I shouldn't be let near the TLS Library
|
||||
0
content/posts/homelab.md
Normal file
0
content/posts/homelab.md
Normal file
71
content/projects/hookengs.md
Normal file
71
content/projects/hookengs.md
Normal file
@@ -0,0 +1,71 @@
|
||||
---
|
||||
title: "Hooking Engine Deatmatch"
|
||||
description: "Evaluating various hooking engines, putting them against pathologically hard to hook functions"
|
||||
date: 2020-02-26T22:00:00+01:00
|
||||
draft: false
|
||||
---
|
||||
|
||||
For the full code see the [git repo](https://vcs.wacked.codes/wacked/hook_tests).
|
||||
|
||||
Introduction
|
||||
============
|
||||
This project aims to give a simple overview on how good various x64 hooking
|
||||
engines (on windows) are. I'll try to write various functions, that are hard to
|
||||
patch and then see how each hooking engine does.
|
||||
|
||||
I'll test:
|
||||
|
||||
* [EasyHook](https://easyhook.github.io/)
|
||||
* [PolyHook](https://github.com/stevemk14ebr/PolyHook)
|
||||
* [MinHook](https://www.codeproject.com/Articles/44326/MinHook-The-Minimalistic-x-x-API-Hooking-Libra)
|
||||
* [Mhook](http://codefromthe70s.org/mhook24.aspx)
|
||||
|
||||
(I'd like to test detours, but I'm not willing to pay for it. So that isn't
|
||||
tested :( )
|
||||
|
||||
There are multiple things that make hooking difficult. Maybe you want to patch
|
||||
while the application is running -- in that case you might get race conditions,
|
||||
as the application is executing your half finished hook. Maybe the software has
|
||||
some self protection features (or other software on the system provides that,
|
||||
e.g. Trustee Rapport)
|
||||
|
||||
Evaluating how the hooking engines stack up against that is not the goal here.
|
||||
Neither are non-functional criteria, like how fast it is or how much memory it
|
||||
needs for each hook. This is just about the challenges the function to be
|
||||
hooked itself poses.
|
||||
|
||||
Namely:
|
||||
|
||||
* Are jumps relocated?
|
||||
* What about RIP adressing?
|
||||
* If there's a loop at the beginning / if it's a tail recurisve function, does
|
||||
the hooking engine handle it?
|
||||
* How good is the dissassembler, how many instructions does it know?
|
||||
* Can it hook already hooked functions?
|
||||
|
||||
At first I will give a short walk through of the architecture, then quickly go
|
||||
over the test cases. After that come the results and an evaluation for each
|
||||
engine.
|
||||
|
||||
I think I found a flaw in all of them; I'll publish a small POC which should at
|
||||
least detect the existence of problematic code.
|
||||
|
||||
**A word of caution**: my results are worse than expected, so do assume I have
|
||||
made a mistake in using the libraries. I went into this expecting that some
|
||||
engines at least would try to detect e.g. the loops back into the first few
|
||||
bytes. But none did? That's gotta be wrong.
|
||||
|
||||
**Another word of caution**: parts of this are rushed and/or ugly. Please
|
||||
double check parts that seem suspicious. And I'd love to get patches, even for
|
||||
the most trivial things -- spelling mistakes? Yes please.
|
||||
|
||||
|
||||
Result
|
||||
========
|
||||
|
||||
| Name|Small|Branch|RIP Relative|AVX|RDRAND|Loop|TailRec|
|
||||
|----------|-----|------|------------|---|------|----|-------|
|
||||
| PolyHook| X | X | X | X | | | |
|
||||
| MinHook| X | X | X | | | | X |
|
||||
| MHook| | | X | | | | |
|
||||
|
||||
BIN
static/img/arm-glibc-strlen/strlen-loop.png
Normal file
BIN
static/img/arm-glibc-strlen/strlen-loop.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 42 KiB |
BIN
static/img/arm-glibc-strlen/strlen-side-by-side.png
Normal file
BIN
static/img/arm-glibc-strlen/strlen-side-by-side.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 62 KiB |
Reference in New Issue
Block a user